Oct. 21, 2025

13 minutes read
Share this article
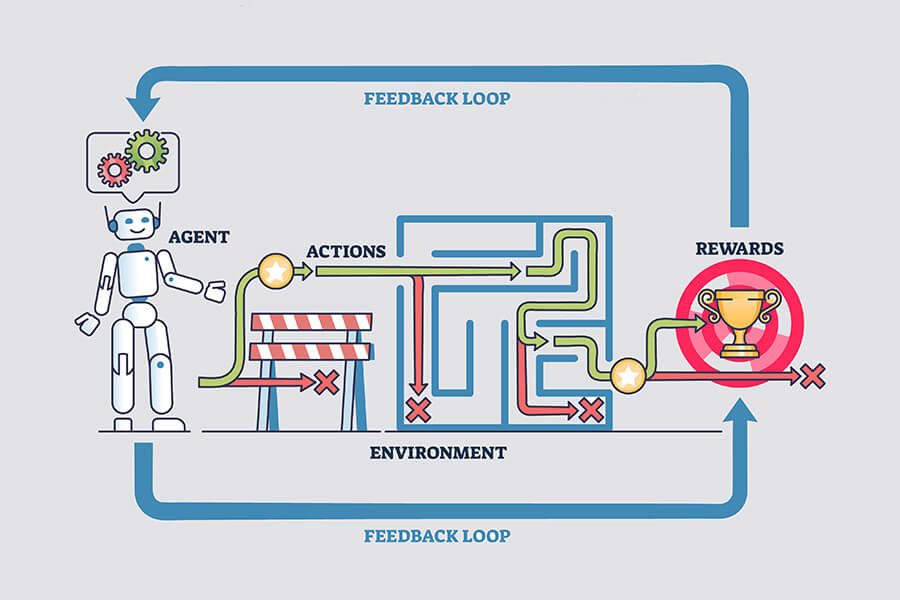
Reinforcement learning is a machine learning approach where an agent learns to make optimal decisions by interacting with an environment and receiving feedback in the form of rewards or penalties. Unlike traditional supervised learning methods for AI that rely on labeled datasets, this approach allows artificial intelligence systems to discover effective strategies through trial and error, much like how humans and animals naturally learn from experience.
The core mechanism involves an agent taking actions within an environment, receiving rewards for beneficial actions and penalties for detrimental ones, then adjusting its behavior to maximize cumulative rewards over time. This feedback loop enables machines to develop sophisticated decision-making capabilities without explicit programming for every possible scenario.
The applications of this technology span from teaching AI to balance objects like poles to powering complex systems in gaming, robotics, and autonomous vehicles. Understanding the fundamental principles, various algorithmic approaches, and real-world implementations reveals why this learning paradigm has become essential for developing intelligent systems that can adapt and improve in dynamic environments.
Reinforcement learning represents a distinct machine learning approach where agents learn through trial and error by interacting with their environment. This learning paradigm differs fundamentally from traditional supervised and unsupervised methods through its focus on maximizing rewards rather than learning from labeled datasets.
Reinforcement learning is a machine learning paradigm where an intelligent agent learns to make optimal decisions through environmental interactions. The agent receives feedback in the form of rewards or penalties based on its actions.
Unlike traditional programming approaches, RL enables systems to develop strategies without explicit programming instructions. The agent discovers successful behaviors by testing different actions and observing their consequences.
This exploratory learning process occurs in an unlabeled environment focused on achieving specific outcomes. The agent continuously refines its decision-making process based on accumulated experience.
Key characteristics of Reinforcement Learning include:
Artificial intelligence systems use RL to master complex tasks like game playing, robotics, and autonomous vehicle control. The learning process mimics how humans and animals naturally acquire skills through practice and feedback.
Reinforcement learning operates fundamentally differently from supervised and unsupervised learning approaches. While supervised learning relies on labeled training data to learn input-output mappings, Reinforcement Learning learns through environmental feedback without predetermined correct answers.
Supervised learning uses datasets containing input-output pairs to train models. The algorithm learns to predict outputs by minimizing errors between expected and actual results. This approach requires extensive labeled data preparation.
Unsupervised learning discovers hidden patterns in unlabeled data without specific target outcomes. These algorithms identify clusters, associations, or dimensionality reductions within datasets.
Reinforcement Learning differs from both approaches by focusing on sequential decision-making in dynamic environments. The agent receives sparse, delayed feedback rather than immediate error corrections.
| Learning Type | Data Requirements | Feedback Type | Learning Goal |
| Supervised | Labeled datasets | Immediate error correction | Predict correct outputs |
| Unsupervised | Unlabeled data | No external feedback | Discover data patterns |
| Reinforcement | Environmental interaction | Delayed rewards/penalties | Maximize long-term rewards |
Self-supervised learning combines elements from multiple paradigms but still differs from RL’s reward-based optimization approach.
The Reinforcement Learning framework centers on dynamic interactions between an agent and its environment. Understanding these core components provides the foundation for grasping how reinforcement learning systems operate.
The continuous feedback loop enables the agent to develop increasingly effective strategies for maximizing cumulative rewards over time.
The learning cycle operates as follows:
Reinforcement learning operates through mathematical frameworks where agents navigate state spaces, select actions, and receive rewards to optimize long-term performance. The learning process balances systematic exploration with reward maximization through continuous trial-and-error interactions.
Markov Decision Processes (MDPs) provide the mathematical foundation for reinforcement learning problems. An MDP consists of states, actions, rewards, and transition probabilities that define how an agent moves through its environment.
The state space represents all possible situations the agent can encounter. Each state contains sufficient information for decision-making without requiring knowledge of previous states.
The action space defines all possible moves available to the agent at any given state. Actions can be discrete (like moving left or right) or continuous (like steering angles in autonomous driving).
State-action-reward loops form the core interaction cycle:
| Component | Function |
| State | Current environment condition |
| Action | Agent’s chosen response |
| Reward | Environmental feedback |
| Next State | Resulting environment condition |
This cycle repeats continuously as agents learn optimal policies. Each interaction provides data that updates the agent’s understanding of which actions yield the highest rewards in specific states.
Trial and error forms the core of reinforcement learning, where agents explore different actions and use feedback to refine their strategies. Unlike supervised learning, agents receive no explicit instructions about correct actions.
Learning occurs through repeated interactions. Agents try various actions, observe outcomes, and adjust their behavior based on the rewards they receive. Poor decisions result in negative feedback, while successful actions generate positive rewards.
Policy updates happen after each interaction. The agent’s decision-making strategy evolves as it accumulates experience. Initially random or suboptimal choices gradually improve through continuous refinement.
Experience accumulation drives improvement. Each trial provides valuable information about action consequences. Agents build internal models of their environment through these repeated experiences, learning which behaviors maximize long-term rewards.
The reward function serves as the primary feedback mechanism that guides agent learning. It assigns numerical values to state-action pairs, indicating the desirability of specific behaviors.
Reward signals shape agent behavior directly. Positive rewards encourage action repetition, while negative rewards discourage similar future choices. The magnitude of rewards influences learning speed and policy development.
Careful reward design prevents unintended consequences. Poorly designed reward functions can lead to unexpected behaviors where agents exploit loopholes rather than achieve intended goals. Clear, well-structured rewards align agent behavior with desired outcomes.
Immediate versus delayed rewards create learning challenges. Agents must balance short-term gains with long-term objectives. The reward function must account for both immediate feedback and future consequences of current actions.
The exploration-exploitation trade-off represents a fundamental challenge in reinforcement learning. Agents must balance trying new actions (exploration) with using known successful strategies (exploitation).
Exploration discovers new opportunities. Agents investigate untested actions and states to find potentially better strategies. Without sufficient exploration, agents may miss optimal solutions by settling for locally good policies.
Exploitation maximizes known rewards. Agents use their current knowledge to select actions with the highest expected returns. Pure exploitation risks missing better alternatives, but ensures consistent performance.
Dynamic environments require ongoing exploration. Reinforcement learning operates effectively in dynamic environments where conditions change over time. Agents must continue exploring to adapt to evolving circumstances and maintain optimal performance.
Balance strategies include epsilon-greedy and upper confidence bounds. These methods systematically alternate between exploration and exploitation, ensuring agents discover new possibilities while leveraging existing knowledge effectively.
Reinforcement learning algorithms fall into distinct categories based on how they approach learning and decision-making. The main divisions include model-based versus model-free approaches, value-based methods like Q-learning, policy-based techniques, and modern deep learning implementations.
Model-based reinforcement learning algorithms create an internal representation of the environment to predict future states and rewards. These methods build a model that estimates how the environment will respond to different actions.
The agent uses this model to plan and evaluate potential action sequences. Model-based approaches can be more sample-efficient since they leverage the learned model for planning.
Model-free methods learn directly from experience without building an explicit environment model. Q-learning and SARSA algorithms represent popular model-free approaches.
These algorithms update value functions or policies based solely on observed transitions. Model-free methods often prove more robust when the environment is complex or partially observable.
The choice between approaches depends on the environment complexity and computational constraints. Model-based methods excel when accurate models can be learned, while model-free methods work better in unpredictable environments.
Q-learning represents one of the most fundamental value-based reinforcement learning algorithms. The algorithm learns action-value functions that estimate the expected return for taking specific actions in given states.
Q-learning uses temporal difference learning to update value estimates. The algorithm updates Q-values based on the difference between predicted and actual rewards plus future value estimates.
Key Q-Learning Features:
SARSA (State-Action-Reward-State-Action) differs from Q-learning in its update mechanism. SARSA updates values based on the actual following action taken, making it an on-policy algorithm.
The algorithm considers the current policy when updating value estimates. This makes SARSA more conservative than Q-learning in specific scenarios.
Both algorithms form the foundation for more advanced value-based methods. They demonstrate how agents can learn optimal behaviors through trial-and-error interactions.
Policy gradient methods directly optimize the policy without explicitly computing value functions. These algorithms adjust policy parameters in directions that increase expected rewards.
The policy network outputs action probabilities for each state. Policy gradients calculate how small parameter changes affect overall performance.
Policy gradients use gradient ascent to maximize expected returns. The algorithms sample trajectories and use them to estimate policy gradients.
REINFORCE represents a basic policy gradient algorithm that uses Monte Carlo methods. More sophisticated variants like Actor-Critic methods combine policy gradients with value function approximation.
These methods excel in environments requiring fine-grained control. They prove particularly effective for robotics and continuous control tasks.
Deep reinforcement learning combines traditional algorithms with deep neural networks. These methods enable agents to handle high-dimensional state spaces like images or complex sensor data.
Deep Q-Networks (DQN) extended Q-learning to work with neural network function approximation. The approach revolutionized reinforcement learning by demonstrating superhuman performance on Atari games.
Deep neural networks serve as function approximators for value functions or policies. The networks learn complex feature representations automatically from raw input data.
Policy gradient methods also benefit from deep learning integration. Deep policy networks can represent sophisticated policies for complex decision-making tasks.
The combination enables reinforcement learning applications in previously intractable domains. Deep reinforcement learning has achieved breakthroughs in game playing, robotics, and autonomous systems.
Reinforcement learning has transformed multiple industries through practical implementations in robotics, autonomous vehicles, strategic gaming, and dynamic environmental control. These applications demonstrate how AI agents learn through trial and error to master complex tasks that traditional programming cannot solve effectively.
Robotics represents one of the most significant areas where reinforcement learning transforms real-world applications. Industrial robots use RL algorithms to learn precise movements for assembly lines and manufacturing processes.
A robotic arm learns to grasp objects of different shapes and weights through repeated attempts. The system receives positive rewards for successful grips and negative feedback for dropped items. This approach eliminates the need for extensive manual programming of every possible scenario.
RL trains machines to walk, grasp, fly, and interact with humans across various robotic platforms. Humanoid robots develop walking gaits by experimenting with different leg movements and balance adjustments.
Medical robotics benefits from RL in surgical procedures where precision is critical. Robotic surgical systems learn to adapt to patient-specific anatomy and tissue variations during operations.
Deep Reinforcement Learning for autonomous driving has become a significant focus for automotive companies worldwide. Self-driving cars use RL to navigate complex traffic situations that cannot be pre-programmed.
The vehicles learn to make decisions about lane changes, merging, and obstacle avoidance through simulation and real-world testing. Each driving scenario provides feedback that improves future decision-making capabilities.
RL algorithms process multiple sensor inputs, including cameras, lidar, and radar, simultaneously. The system learns to prioritize safety while maintaining efficient travel times and passenger comfort.
Extensive safeguards prevent the agent from becoming unsafe in real-world driving applications. Multiple backup systems and human oversight ensure reliability during the learning process.
AlphaGo marked a breakthrough moment when it defeated world champion Lee Sedol in the ancient game of Go. This achievement demonstrated RL’s ability to master strategic thinking in games with virtually infinite possible moves.
The system combined deep neural networks with Monte Carlo tree search algorithms. It learned by playing millions of games against itself, discovering strategies that human players had never considered.
Gaming applications extend beyond traditional board games to video games and esports. RL agents now compete at professional levels in complex strategy games and real-time combat scenarios.
These gaming successes translate to practical applications in military strategy, resource allocation, and competitive business environments where strategic decision-making is essential.
Dynamic environments present constantly changing conditions that require continuous learning and adaptation. RL excels in these scenarios where traditional rule-based systems fail.
Financial trading systems use RL to adapt to market volatility and changing economic conditions. The algorithms learn to recognize patterns and adjust trading strategies based on market feedback.
Energy grid management employs RL to balance supply and demand across power networks. The system learns to optimize energy distribution while accounting for renewable energy fluctuations and peak usage periods.
Climate control systems in smart buildings adapt to occupancy patterns, weather changes, and energy costs. These systems continuously optimize temperature and lighting based on real-time environmental data and user preferences.
Reinforcement learning represents a decisive shift in how we train machines to think, act, and evolve. By embracing trial and error as a core mechanism, AI systems gain the ability to adapt, optimize, and thrive in complex, ever-changing environments.
As we continue to push the boundaries of intelligent technology, reinforcement learning stands out not just as a tool—but as a cornerstone for building truly autonomous and responsive systems. The journey from trial to triumph is just beginning.
Leandro is a Subject Matter Expert in Backend at Coderio, where he focuses on modern backend architectures, AI-assisted modernization, and scalable enterprise systems. He contributes technical thought leadership on topics such as legacy system transformation and sustainable software evolution, helping organizations improve performance, maintainability, and long-term scalability.
Leandro is a Subject Matter Expert in Backend at Coderio, where he focuses on modern backend architectures, AI-assisted modernization, and scalable enterprise systems. He contributes technical thought leadership on topics such as legacy system transformation and sustainable software evolution, helping organizations improve performance, maintainability, and long-term scalability.
Accelerate your software development with our on-demand nearshore engineering teams.





